Requirements analysis: catching requirement bugs before they become code
Every experienced engineer has a story where a feature shipped, worked on the happy path, and then quietly did the wrong thing on some edge case no one had thought about. Trace the bug back far enough and it rarely ends at the code; it ends at a sentence in a requirement document that meant one thing to the person who wrote it and something else to the person who implemented it.
Requirement bugs come in four classes, and they are all very hard to spot on a first read:

Wrong level of detail: the requirement is really a thesis statement ("the system shall support authentication") or an implementation recipe ("the system shall use JWT tokens with a 15-minute TTL"), not a testable constraint on observable behavior.
Ambiguity: the same sentence has two plausible interpretations, and two developers would implement it differently. We are typically not conscious of our own interpretation bias so what appears crystal clear to you may not be that clear for someone else with a different interpretation bias.
Inconsistency: two requirements, each sensible in isolation, cannot both hold at the same time. This is typically discovered late in the development process and forces arbitration. Different developers may resolve the conflict differently, and in some cases problems are resolved at the implementation level without being raised and clarified at the specification level.
Incompleteness: the requirement describes what the system must do only on some inputs, leaving behavior unspecified for whole regions of the input space. Different developers may decide to act differently on these inputs and introduce unspecified behavior.
Level of detail and ambiguity problems are hard to detect because they are about what is not explicitly stated in the specification and how different people or AI coding agents may interpret the requirements. Inconsistency problems are hard to detect because they require reasoning over several requirements simultaneously to find common triggers and analyze consequences. Completeness problems are also hard to detect, because they require reasoning over the whole specification at once to see if there are any gaps left.
AI-assisted engineering makes this problem worse in two ways. First, the prompt you give to the agent is the de-facto requirement now. Your initial prompt is the only tangible artifact that captures "what do we want to build". Every vague prompt produces a vague spec or plan, and the AI agent implementing that spec produces code full of undisclosed decisions made on your behalf, without your awareness or agreement. Second, AI agents generate code faster than humans can review it, so the gap between what you meant to build and what got built keeps widening.
This is not a hunch. Recent work that experimented with mutating clear prompts into ambiguous, incomplete, or contradictory prompts shows Pass@1 drops of 20–40%, with 60–90% of the syntactically valid code being semantically wrong (Larbi et al., 2025). The code works but doesn’t do what you want it to do. A separate study on prompt underspecification finds that LLMs silently fill in the gaps for unspecified requirements, and that underspecified prompts are about twice as likely to regress across model or prompt changes, sometimes with accuracy drops exceeding 20% (Yang et al., 2025). The code compiles, the tests pass, and the behavior still diverges from what was intended, because newer models fill in the gaps with an undisclosed and different bias than previous models. Vague specs have a measurable cost, and the cost surfaces only after spending tokens generating a first version of the code.
Kiro's spec-driven workflow addresses this by walking developers through a more structured workflow for agentic development: Prompt → Requirements → Design → Tasks → Code. Your initial chat with the agent produces explicit requirements in EARS notation. Kiro turns them into a design document that materializes architectural and algorithmic decisions, defines a verification strategy through property-based tests, and produces a task list. The agent then executes each task with the specification and design as reference.
The specification document is the source of truth in that process, but it can still suffer from the problems described above.
That’s why we introduced requirements analysis, a new optional step in Kiro's workflow that analyzes your requirements.md for the classes of problems listed above, before any design or code is generated. Requirements analysis uses neuro-symbolic techniques to verify that requirements have the right level of detail, flag acceptance criteria that accept multiple plausible interpretations, and detect contradictions or completeness gaps. Each type of finding gets surfaced as a simple two-option question. You pick an answer (or you let an LLM-based critic select an answer for you); the requirement gets updated; the pipeline continues. Under the hood, the analysis automatically encodes the specification into formal logic using LLMs and uses SMT solvers to generate the findings, but you don’t need a background in formal methods to use this and the formalization is kept out of sight.
The hard part of specification engineering is that there is no oracle for specification correctness other than the user. Only you know what you actually meant and whether or not the specification captures your intent. How can anything be checked automatically if the ground truth lives in someone's head? Luckily, beyond capturing the specific intent for any one system, every specification must obey a handful of generic quality properties that are domain-independent. These can be checked automatically. What remains, choosing the interpretation that best aligns with actual intent, is where the user has to weigh in. Requirements analysis automates the first part and surfaces the second part as a small number of concrete questions that the user can answer quickly.
The generic properties we expect any reasonable specification to have are:
Testable. A good specification must describe observable conditions on observable quantities. Reading it, you should be able to name the inputs, the outputs, and the conditions under which the system response is as required. "The system shall authenticate users" fails this test: you cannot name an output. "When a user submits credentials that match a valid account, the system shall return an authenticated session token" passes, because inputs, outputs, and the condition are all explicit.
Solution-free. A good requirement describes what the system does, not how. "The system shall implement soft deletion to retain records in the database for audit" prescribes a mechanism. "When a record is marked as deleted, the system shall exclude it from user-facing views while retaining it for administrative access" describes the observable behavior and leaves the implementation open.
Unambiguous. Two independent readers would formalize an unambiguous requirement in the same way. "The system shall remove the record" is ambiguous: one reader hears hard delete and another hears soft delete. "The system shall mark the record as deleted such that it is no longer visible in any user-facing view" pins down the observable outcome.
Consistent. Taken together, the requirements must admit at least one implementation, meaning there must be no situation where two acceptance criteria require incompatible behaviors from the system.
Complete. System behavior must be specified under any input combination; there must be no state where the requirements don't prescribe what the system should do.
These properties are not new: they come from decades of systems engineering practice. What is new is that LLMs can now do most of the work of enforcing them automatically: rewriting vague requirements into testable ones, spotting when implementation language has leaked into a specification. Through our experiments, we noticed that most requirements generated from the initial conversation with the agent about a feature idea start out thesis-level: too vague or too abstract to meaningfully formalize and analyze for consistency or completeness. That is not a knock on Kiro or on LLMs, a human would produce a similar first draft. The point is that the first draft is just the starting point for a pass of refinement that is supposed to bring requirements to the right level of detail, at which formalization, consistency and completeness analysis become actually worth doing.
What is also new is that neuro-symbolic techniques allow translating natural language into formal logical statements and automatically detecting consistency and completeness problems. What neuro-symbolic techniques cannot do is decide for you, out of several plausible formal interpretations of a requirement, which one actually matches your original intent. Nevertheless, we can help you decide without drowning you in formal logic by generating scenarios that reveal semantic divergence, precisely locating the root cause of the divergence, and presenting that back to you as two-choice questions that let you clarify your own interpretation.
The requirement analysis pipeline contains three main stages: first we have refinement (to bring requirements to a level of detail appropriate for formalization), then auto-formalization (where requirements get automatically translated to formal logic using an LLM), and lastly logical analysis where an automated reasoning engine analyses completeness and consistency of the of the formalized requirements.
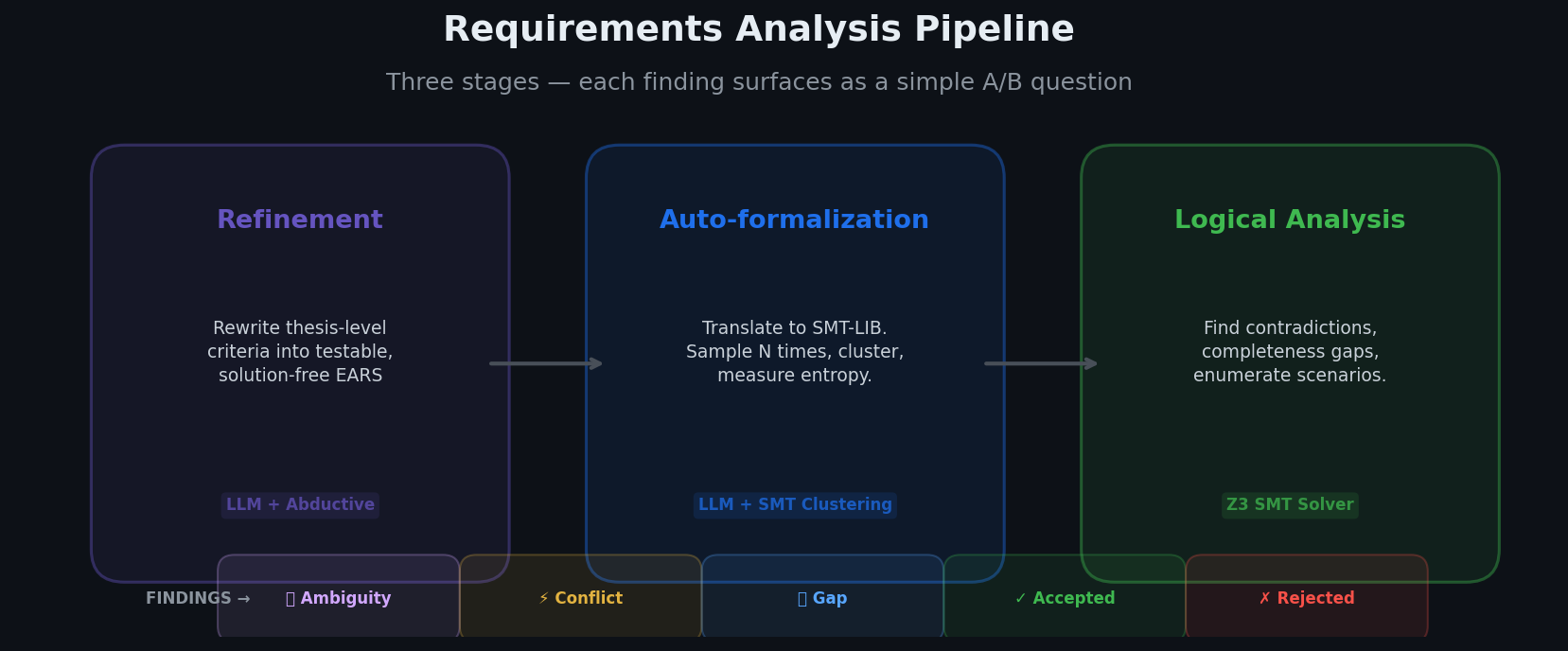
The refinement stage produces new EARS acceptance criteria. The auto-formalization and logical analysis phases produce different types of technical findings. However, in order to make the user experience more uniform, each type of technical finding is translated into a natural language question with two possible answers: Answer A always means keep the requirement as-is; Answer B always means change it in some way, with a specific proposal.
Here is an example of an ambiguity finding for a "Delete Property" requirement. Ambiguity findings are detected during the auto-formalization stage when we figure out that a given acceptance criterion admits multiple semantically divergent translations into logic:
The technical ambiguity finding would be surfaced as the question
The phrase "remove the record" could mean the record is gone entirely, or marked as deleted and retained for audit. Which did you mean?
A) Keep as-is: the record is gone.
B) Change: the record is retained but hidden from user-facing views.
We surface five types of findings this way:
Ambiguity questions: a sentence has two plausible meanings and you pick one.
Conflict questions: two rules can fire in the same situation and demand incompatible outcomes; you pick which wins, or narrow one.
Completeness questions: a reachable situation has no rule defining behavior; you decide whether that silence is intentional.
Accepted-scenario questions: the spec currently allows some behavior (using cached data when fresh is available, for example); you confirm the permission is intended.
Rejected-scenario questions: the mirror. The spec currently forbids some behavior (rejecting whitespace-only queries before trimming); you confirm the prohibition is intended.
The rest of this post is about how requirements analysis produces those questions. We have three stages: refinement rewrites thesis-level sentences into testable ones; auto-formalization translates natural language into a formal model; logical analysis uses that model to find contradictions, gaps and enumerate examples of system behaviors that are either accepted or rejected by the requirements.
Before analyzing consistency or completeness with neuro-symbolic techniques, requirements need enough detail and structure for the formalization and analysis to be worth doing. A thesis-level acceptance criterion like "the system shall implement soft deletion" formalizes into a single opaque boolean: there is not much to reason about. Refinement is the step that turns thesis-level sentences into testable, solution-free criteria that name their events, inputs, states and outputs, and logical conditions that must hold between them with enough precision.
Requirements analysis refines coarse grain requirements automatically by using an LLM and working backwards from the user story using an abductive reasoning approach. Refinement requires context understanding and creativity, which is why it is driven by an LLM. Given the story "as a property owner, I want to delete a property, so that I can remove properties I no longer manage," and the initial version of acceptance criteria, the refinement process asks what the success state looks like and what prerequisites must hold for that state to be reached without failure. For each prerequisite, it asks: what could prevent this? What error paths should exist? Is the condition already captured by an existing acceptance criterion, or does a new one need to be added? Along the way, it checks each existing acceptance criterion for EARS pattern misuse, vague qualifiers and implementation-level language. This is all done for you behind the scenes, automatically.
Here is what that looks like on a real example. The original "Delete Property" requirement has five acceptance criteria:
WHEN a Property Owner initiates property deletion, THE Platform SHALL prompt for confirmation before proceeding
WHEN a Property Owner confirms deletion, THE Platform SHALL remove the Property record from the Platform
WHEN a Property is deleted, THE Platform SHALL display a confirmation message and redirect to the properties list
THE Platform SHALL implement soft deletion to retain Property records in the database for audit purposes while hiding them from the user interface
WHEN a Property Owner attempts to delete a Property that does not belong to their User Account, THE Platform SHALL deny the deletion and display an authorization error message
Read one at a time, the acceptance criteria look fine. However, the refinement analysis surfaces, three kinds of problems:

Criterion 2 contradicts Criterion 4. Criterion 2 says "remove the record," which is a hard delete. Criterion 4 says "implement soft deletion to retain records in the database," so the record stays. Which is it? A developer reading the spec would have to guess.
Criterion 4 mixes what and how. "Implement soft deletion" and "retain records in the database" are implementation choices. The observable conditions we want are not stated clearly: the record must remain retrievable for audit access, but must not appear in user-facing views.
Criterion 5 uses the wrong EARS pattern. "Does not belong to their User Account" is an error condition. In EARS, error conditions must use the IF-THEN pattern; WHEN patterns are for nominal conditions. A well-formed rewrite would be: "IF the property does not belong to the requesting user, THEN the Platform SHALL reject the deletion."
Refinement fixes all three, and then goes further, working backward from the success state to ask what could prevent a successful deletion. What if the property doesn't exist? What if it has active leases? What if the user cancels the confirmation prompt? None of these paths are covered by the initial requirement. Three new acceptance criteria get added to fill the gaps. The end result is five amended acceptance criteria (contradiction resolved, implementation language removed, EARS patterns corrected) plus three new acceptance criteria covering the missing error paths:
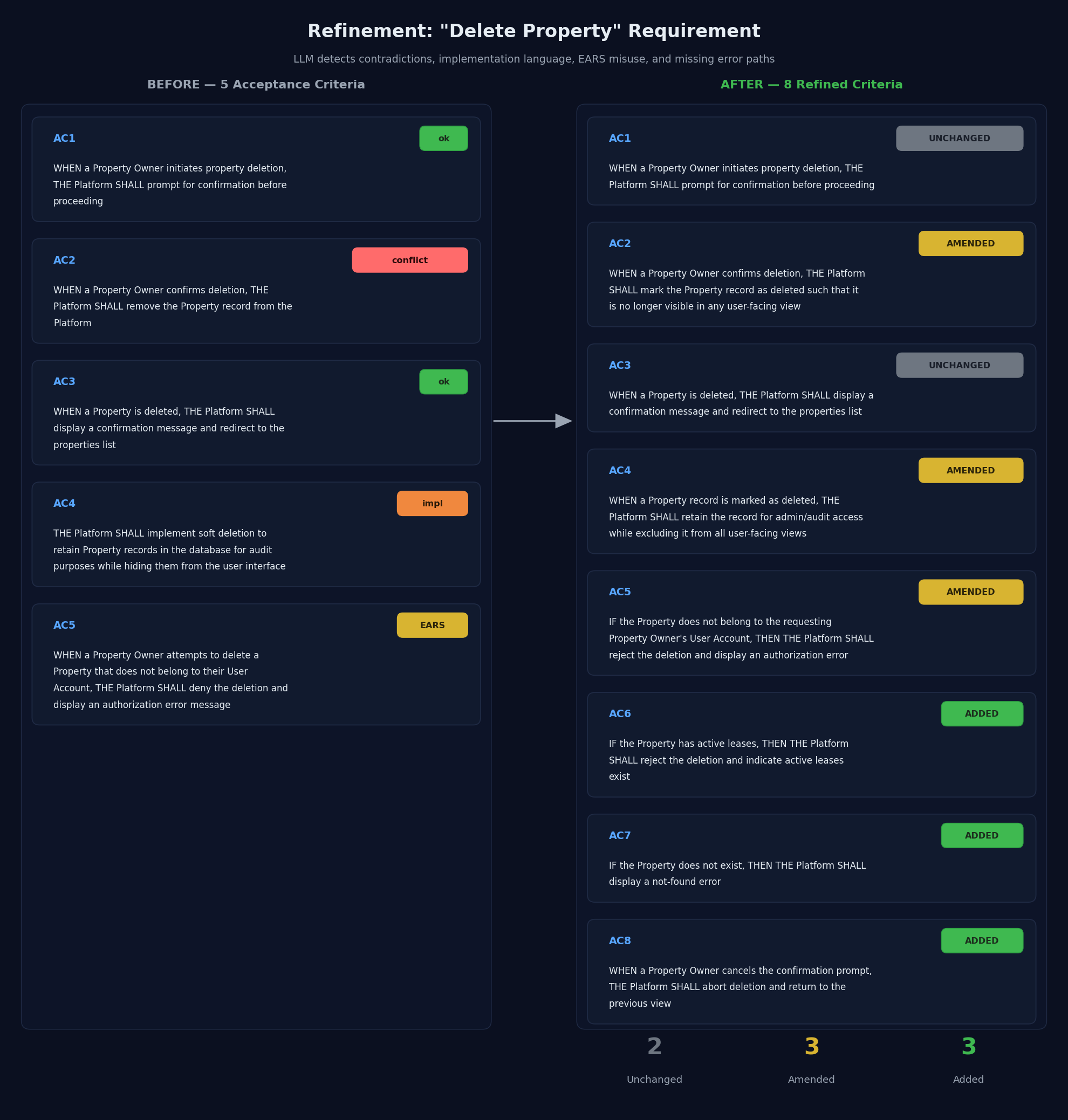
The detailed text of the refinement requirements:
WHEN a Property Owner initiates property deletion, THE Platform SHALL prompt for confirmation before proceeding (UNCHANGED).
WHEN a Property Owner confirms deletion, THE Platform SHALL mark the Property record as deleted such that it is no longer visible in any user-facing view (AMENDED).
WHEN a Property is deleted, THE Platform SHALL display a confirmation message and redirect to the properties list (UNCHANGED).
WHEN a Property record is marked as deleted, THE Platform SHALL retain the record for admin/audit access while excluding it from all user-facing views (AMENDED).
IF the Property does not belong to the requesting Property Owner's User Account, THEN THE Platform SHALL reject the deletion and display an authorization error (AMENDED).
IF the Property has active leases, THEN THE Platform SHALL reject the deletion and indicate active leases exist (ADDED).
IF the Property does not exist, THEN THE Platform SHALL display a not-found error (ADDED).
WHEN a Property Owner cancels the confirmation prompt, THE Platform SHALL abort deletion and return to the previous view (ADDED).
The rewritten requirement and its acceptance criteria are now testable, solution-free, and without immediately apparent internal contradictions. Refinement cannot rule out ambiguity completely, because some words really do have more than one plausible meaning, and it cannot guarantee the set of rewritten criteria is actually logically consistent and complete as a whole. However, the refined requirement is now amenable to formalization into logic, which will then allow us to check whether formalized acceptance criteria are actually logically consistent and complete. Formalization also enables scenario generation: examples of scenarios accepted or rejected by your requirements allow you to check that your intent is well captured by the requirements. Formalization is the step where we detect acceptance criteria that are ambiguous in the sense that they accept more than one plausible encoding in logic, and require user intent clarification.
Once a requirement is at the right level of detail, the next step is to translate it into a formal logical model that an automated reasoning engine can analyze. Today, the formal model is expressed in the formal language SMT-lib. Concretely, it has three parts:
A schema declaring the formal symbols the requirements talk about: the entities (e.g.
Property,Order), their attributes (e.g.order_state,inventory_available), the events that can occur (order_submitted,order_canceled), the inputs, and the outputs (what the system does in response). Each symbol carries a short natural-language description so it can be traced back to the source text.A set of assertions encoding acceptance criteria as logical implications
antecedent => consequentexpressed over the symbols declared in the schema. Each EARS clause maps cleanly to an implication: the WHERE/WHILE/WHEN/IF clauses become the antecedent, the THE ... SHALL clause becomes the consequent.A set of background assertions, that models additional constraints between symbols of the schema that encode implicit background knowledge about how symbols are related, but not explicitly mentioned in the requirements: for instance, durations are positive (
duration >= 0), when the variabletimeout_occurredis true, then it means thatduration > max_duration, etc.
The formalization is done by an LLM. LLM translation has one important quirk: it is non-deterministic. Ask for the formal version of the same acceptance criterion ten times and you may get several different answers. Sometimes the differences are cosmetic (variable names, ordering of conditions in a conjunction). Sometimes they are semantic: one sample decides "remove the record" means hard delete while another decides it means "soft delete"; one sample reads "duration is positive" as strictly greater than zero while another allows zero in the range. These differences are exactly the kinds of ambiguity problems we try to detect: they reveal genuine ambiguity in the natural language, or places that result in LLM confusion, surfacing as semantically divergent formal encodings.
We turn this nondeterminism into a detection mechanism by measuring the semantic entropy of the translation. We sample multiple candidate formalizations of each requirement and use the automated reasoning engine to cluster them by logical equivalence: candidates that behave identically under all possible inputs land in the same cluster (even if they differ syntactically), while candidates that diverge on at least some inputs land in different clusters. Semantic entropy measures how much the LLM disagrees with itself about the meaning of the requirement, and we define two configurable thresholds low_entropy and high_entropy:
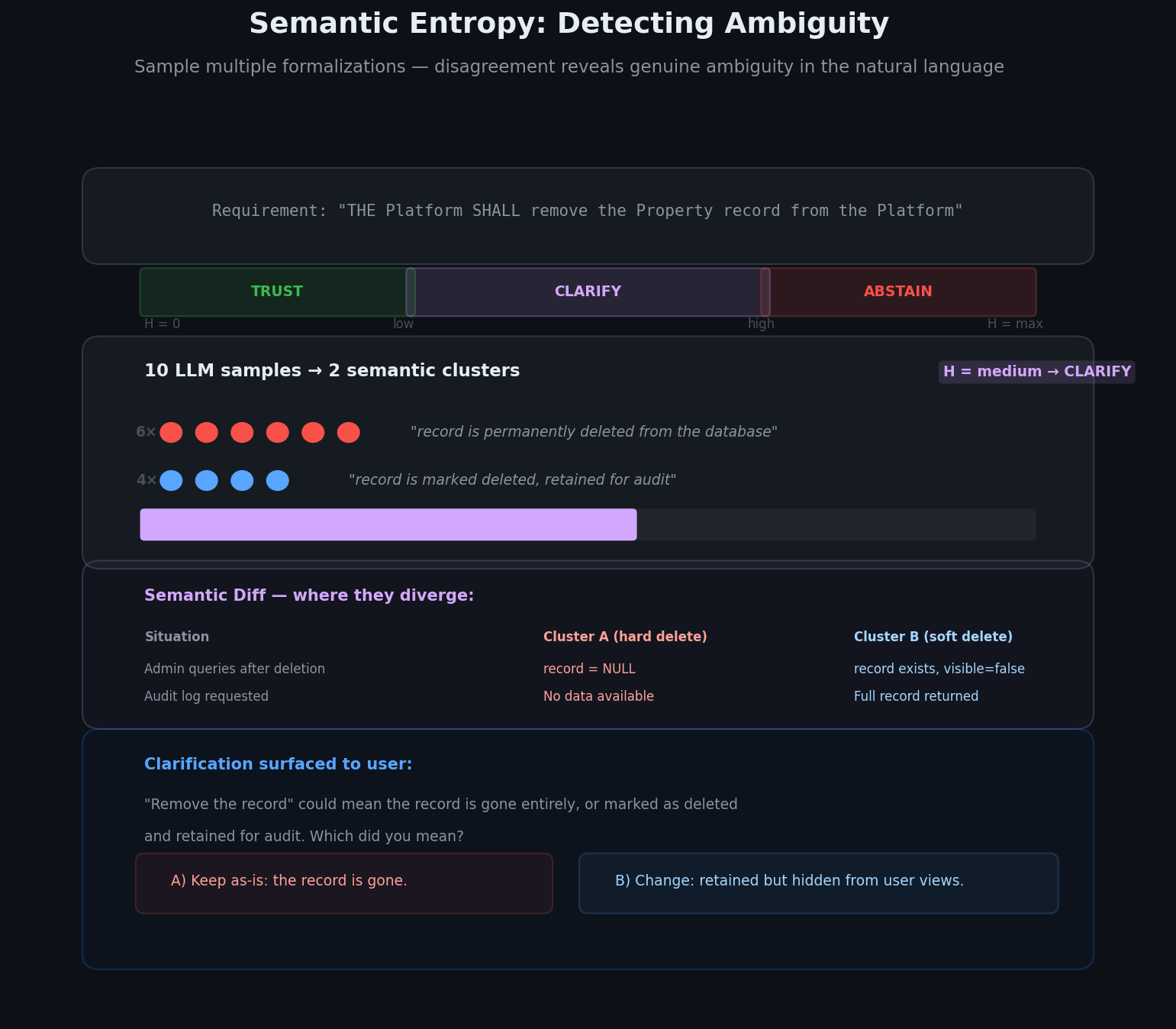
Semantic Entropy is below low_threshold: the LLM is confident. We trust the formalization and select the majority cluster representative as formal interpretation of the natural EARS statement.
Semantic Entropy is above the high_entropy threshold: the LLM cannot formalize the EARS statement reliably and is most likely hallucinating, so we abstain from using the result of the translation. The EARS statement needs to be reformulated.
Semantic Entropy is between the low_entropy and high_entropy thresholds: The LLM robustly produces a few dominant interpretations of the EARS statement. This calls for user clarification. We compute a
semantic diff between the top two candidates, a precise characterization of the situations in which candidates diverge and which part of the EARS statement gets formalized differently between candidates. The formal semantic diff then gets translated back into a clarification question in natural language: "in this situation, these two readings disagree on whether the record still exists after deletion, which one did you mean?"
How well does auto-formalization actually work in practice? A study from MIT and Airbus on LLM-assisted requirements engineering at Airbus scale found strong results for classification and entity extraction, but weak evidence for requirement formalization and generation (Norheim et al., 2024). Our own evaluation tells a more nuanced story. LLMs appear quite good at refining and formalizing individual acceptance criteria as explicitly stated in the requirement documents. What needs more work in the future is extracting implicit domain knowledge from the user and from LLMs. Implicit domain knowledge is the "dark matter" of requirements that makes them hold together, that we as humans do not typically write down because all people operating in the same domain are already aware of it: the fact that an order cannot be canceled before it was submitted, that a property cannot have two active owners, that a refunded payment cannot be refunded again. Without that explicit model of what is and is not possible in the domain, the automated reasoning engine can detect ambiguity, inconsistency and incompleteness problems that can occur in situations that are impossible under these implicit constraints. Requirements analysis as released today addresses this aspect by sampling background knowledge assertions from the LLM multiple times and retaining a subset based on a frequency threshold. But to truly unlock requirement analysis at scale, building good formal domain models is where most potential improvement lives.
With a formal model in hand, the reasoning engine can reliably answer questions such as: is there any situation in which all the acceptance criteria hold simultaneously? Is there any situation in which none of them apply? Is there any pair of assertions whose antecedents can activate simultaneously while their consequents are inconsistent
Here is an example to make this more concrete. Five acceptance criteria for an order processing system, specifying the interaction between order emission, order cancellation, refunds and backordering:
R1. WHEN an order is submitted AND inventory is available for the order, THE Order System SHALL fulfill the order.
R2. WHEN an order is submitted AND inventory is not available for the order, THE Order System SHALL place the order on backorder.
R3. THE Order System SHALL NOT place any order on backorder.
R4. WHEN an order is canceled, THE Order System SHALL refund all payments associated with the order.
R5. WHILE an order is in a canceled-and-refunded state, THE Order System SHALL NOT fulfill the order.
Each requirement looks reasonable in isolation. But the set as a whole cannot be implemented because they contradict each other. Auto-formalization produces a schema with a few event variables (order_submitted, order_canceled), a few state variables (inventory_available, order_state), and a few outputs (order_fulfilled, order_backordered, payments_refunded). Each requirement becomes a single implication:
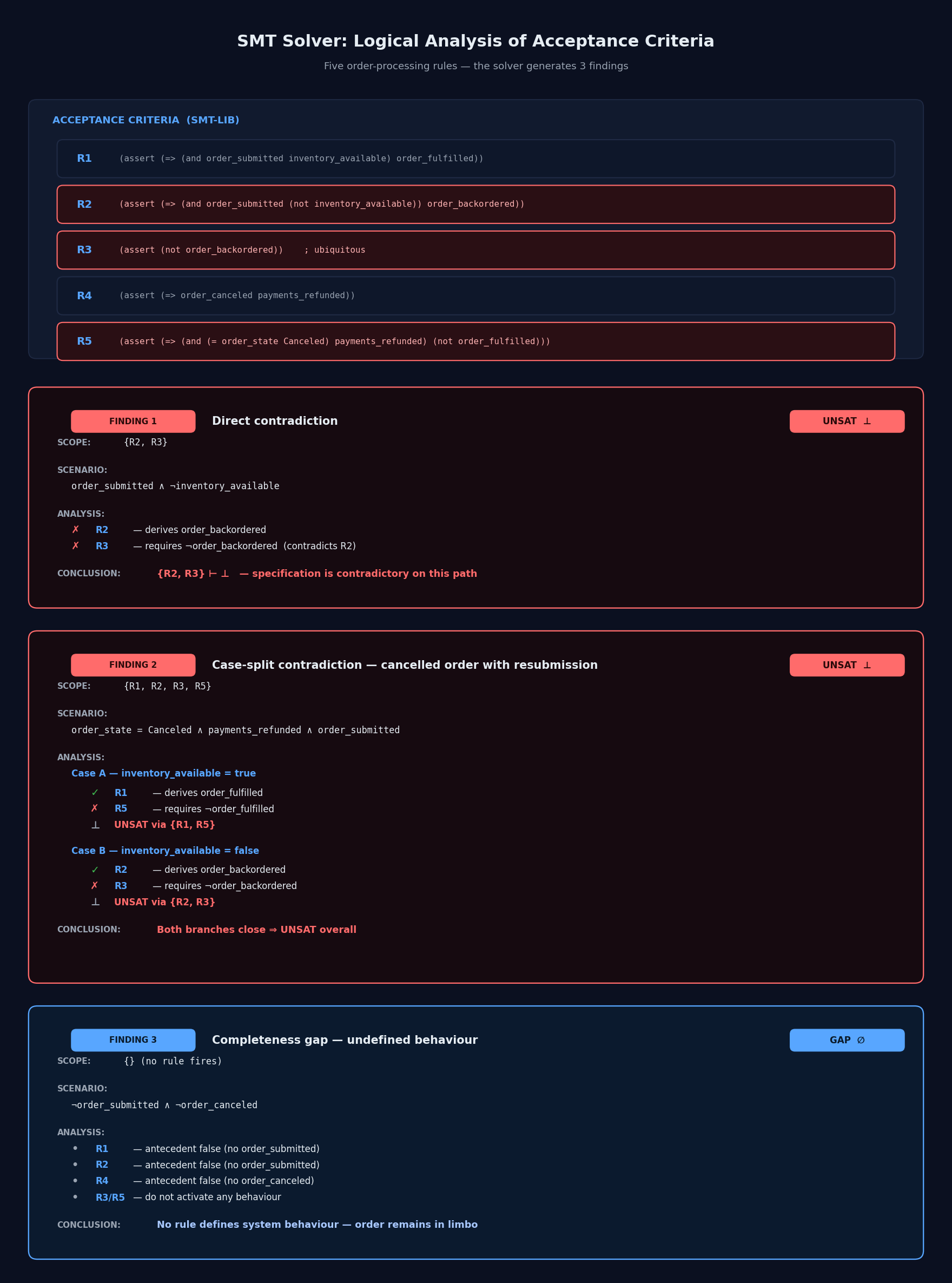
The first finding is an obvious conflict. We ask the reasoning engine whether there is a situation where all five rules hold and R2's guard is active. Answer: unsatisfiable. When an order is submitted and inventory is not available, R2 requires the order to be placed on backorder, and R3, the ubiquitous rule, forbids exactly that. The engine returns the minimal set of rules responsible for the contradiction: {R2, R3}. A careful reader could catch this one by eye, but the engine catches it automatically.
The second finding is a conditional contradiction that involves several rules and reasoning using case splits. The engine checks a scenario with four conditions: the order is in a canceled-and-refunded state, and a new order_submitted event arrives (Imagine a customer re-submitting a previously canceled order). The engine case-splits on inventory availability:
Inventory available. R1 says fulfill. R5 says don't fulfill. There is a contradiction on output
order_fulfilled. The subset of contradictory rules is {R1, R5}.Inventory not available. R2 says backorder. R3 says don't backorder. There is a contradiction on output
order_backordered. The subset of contradictory rules is {R2, R3}.
Either way, no implementation can satisfy all five rules, since there is no feasible path through these rules that does not result in a logical contradiction.
The third finding is a completeness gap. We ask the reasoning engine: is there a situation in which none of R1, R2, R4, or R5 applies? (R3 is ubiquitous and always applies, but that is exactly the point: a ubiquitous rule does not define behavior for a particular scenario, it just imposes a blanket constraint.) Answer: yes. When order_submitted = false, order_canceled = false, and the order is not canceled-and-refunded, none of the rules fire. The order may be present in the system but sitting in some state with no rule telling the system what to do. To make the specification complete we have to add an additional rule describing expected system behavior in that situation.
The automated reasoning engine produces two more kinds of findings:
accepted scenarios: examples of concrete system behaviors allowed by the requirements
rejected scenarios: examples of concrete system behaviors
forbidden by the requirements
These behaviors are sampled directly from the formal model, and can help the user confirm that their intent was accurately captured (you can think of scenario generation as "simulating the specification"). However, there can be far too many scenarios to show. To prevent flooding the user with scenarios, we use an LLM judge to analyze each scenario in the context of the user story. In essence, we ask the LLM judge to answer the question: “Is the fact that this system behavior is accepted (respectively, rejected) surprising, considering what we are trying to achieve in the user story?”
For scenarios judged as surprising, we surface a question to the user describing the accepted (respectively rejected) scenario and offering two options. Option A: keep the requirement as is; Option B: change the requirement to reject (respectively accept) the scenario. By selecting option A, the user acknowledges that this scenario is accepted (or rejected) as desired. By selecting option B, the user confirms that the scenario is surprising, and triggers a revision of the requirement.
Requirement bugs are expensive. They propagate through detailed design, into task planning, and finally into code, are hard to detect on first read, and costly to fix. AI-assisted coding makes the stakes higher, because code being generated from vague specifications can land in production faster than any human can review it for these classes of subtle bugs.
Requirements analysis helps raise the quality of your specifications in three steps using a neuro-symbolic approach: First, refinement uses LLM-driven reasoning to turn thesis-level requirements into more testable, solution-free, and more consistent and complete requirements. Second, auto-formalization produces a formal model that represents the natural language faithfully, detecting semantic ambiguity on the fly and asking for clarification where needed. Third, logical analysis uses an automated reasoning engine to detect consistency and completeness problems on the formal model, and generate scenarios exemplifying accepted and rejected system behaviors. Each finding is surfaced as a concise question with two concrete answer options. Once you've answered the questions, an LLM rewrites the affected requirements to reflect your choices explicitly, producing an updated specification that is better aligned with your intent, ready for detailed design and implementation.
The EARS notation Kiro uses in requirement documents
INCOSE's Guide to Writing Requirements codifies requirements properties in more detail
Larbi, M., Akli, A., Papadakis, M., Bouyousfi, R., Cordy, M., Sarro, F., & Le Traon, Y. (2025). When Prompts Go Wrong: Evaluating Code Model Robustness to Ambiguous, Contradictory, and Incomplete Task Descriptions. https://arxiv.org/abs/2507.20439.
Yang, C., Shi, Y., Ma, Q., Liu, M. X., Kästner, C., & Wu, T. (2025). What Prompts Don't Say: Understanding and Managing Underspecification in LLM Prompts. arXiv preprint arXiv:2505.13360.
Norheim JJ, Rebentisch E, Xiao D, Draeger L, Kerbrat A, de Weck OL. Challenges in applying large language models to requirements engineering tasks. Design Science. 2024;10:e16. doi:10.1017/dsj.2024.8.