Sonnet 5 is now available in Kiro
Starting today, Claude Sonnet 5 is available in Kiro IDE, CLI, and Web. It’s Anthropic’s most agentic Sonnet model yet, a substantial upgrade from Sonnet 4.6, with stronger reasoning, tool use, and coding — and at Sonnet-class pricing.
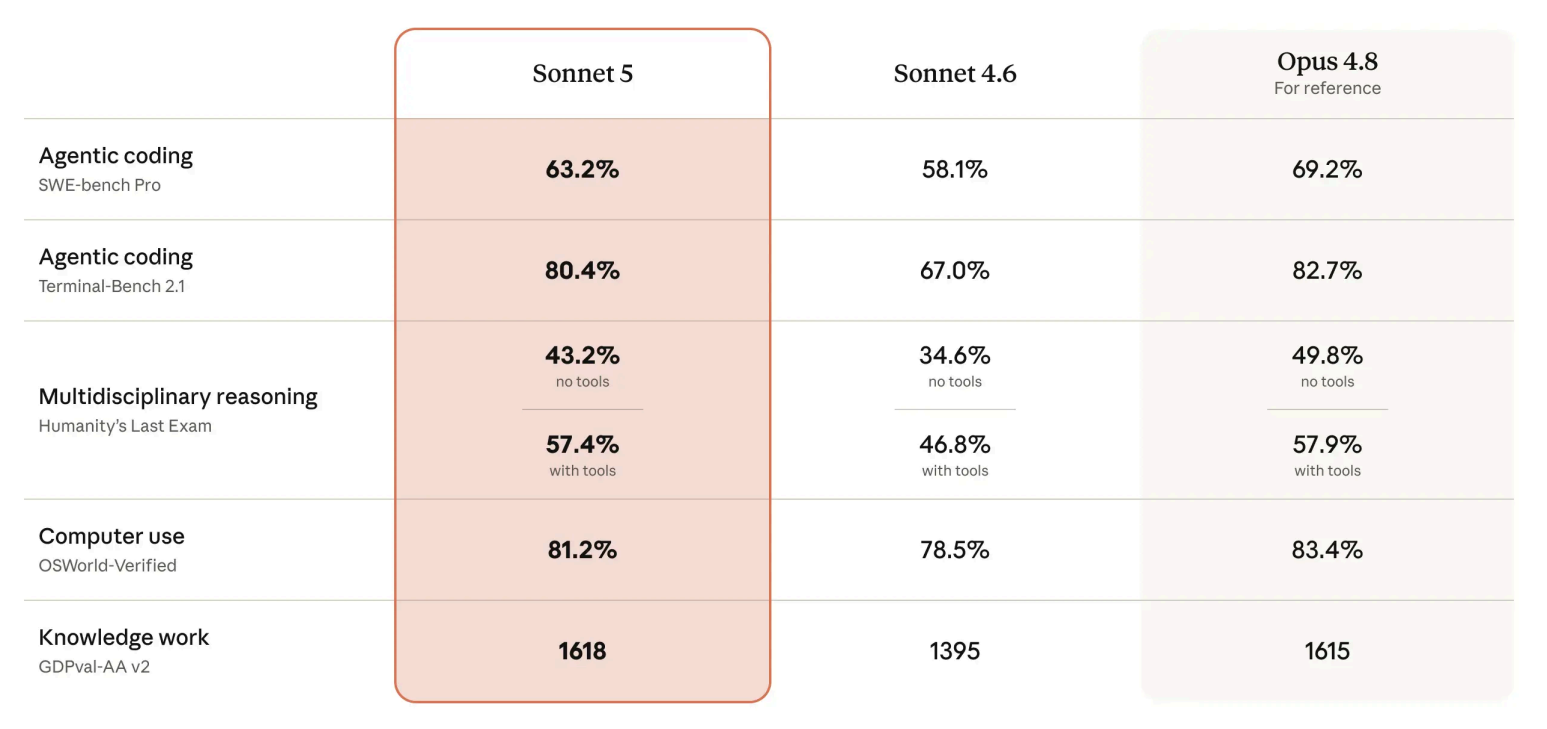
For many developers, the agentic AI era began with Sonnet-class models. More recently, the clearest gains in agentic capability have shown up in the Opus line. Sonnet 5 narrows that gap. Its performance approaches Opus 4.8 on reasoning, tool use, coding, and knowledge work, at meaningfully lower cost.
In Kiro, that gives you a real cost-performance dial. Use Opus 4.8, when you want maximum accuracy on the hardest work; use Sonnet 5 when you want strong agentic behavior at a price point that lets you run more of it. Between the two, you can adjust effort levels to find the right balance for each task.
Across the Kiro IDE, CLI, and Web, Sonnet 5 plans before it edits, runs longer without supervision, and checks its own output without being explicitly asked. Early testers consistently described it as finishing complex tasks where prior Sonnet models would stop short.
For spec-driven workflows in the IDE, that translates to higher-fidelity implementation across broader changes with less drift from the spec. For the CLI and Web, multi-step agentic tasks — browsing, terminal use, multi-file refactors — run to completion more reliably, with fewer dead ends and less need to supervise closely.
Sonnet 5 is rolling out gradually with experimental support to Kiro Pro, Pro+, Pro Max, and Power customers in the AWS US-East-1 (Northern Virginia) and AWS Europe (Frankfurt) regions, with cross-region inference support. It ships with the full 1M context window, 1.3x credit multiplier, the same as Sonnet 4.6.
A note on tokenizer changes: Sonnet 5 uses an updated tokenizer that processes text slightly differently than Sonnet 4.6. The same input can map to roughly 1.0–1.35x more tokens depending on content type.
Download Kiro or restart the IDE or CLI to check for the latest available models. Web users can refresh their browser to see Sonnet 5 in the model selector.