From OpenAPI/Swagger specifications to test suite in seconds with Kiro
Sumitha AP
Solutions Architect
Rajdeep Mukherjee
Applied Science
APIs are the backbone of modern applications. As teams build and iterate on REST APIs, maintaining comprehensive test coverage becomes a persistent challenge. OpenAPI/Swagger specifications do a remarkable job of describing what an API should do: the endpoints, request shapes, response schemas, and status codes. What they don't do is prove any of it works.
Closing that gap traditionally falls on developers. You read the specifications, translate each endpoint into test cases, account for happy paths and edge cases, wire up a test runner, mock dependencies, and build enough reporting to make the results meaningful. For a moderately sized API, say 40 endpoints, that's a week of work before you've written a single line of product code. And that's assuming the specification stays stable, which it rarely does.
The core challenge is that API specifications and their corresponding test suites are maintained independently. Over time, they inevitably diverge. Tests written at launch grow stale as endpoints change. New endpoints ship without accompanying test coverage.
Tools like OpenAPI Generator can produce test scaffolding from a specification, but they typically give you stubs to fill in yourself. Kiro takes a different approach by treating the specification as the source of truth for test generation. Feed it an OpenAPI/Swagger file, and it produces a working test suite, endpoint coverage, edge cases, schema validation, and reporting scaffolding, in the time it would take you to set up a test file. Furthermore, Kiro reduces the cost of keeping tests in sync with the spec by making regeneration fast and low-effort, and hooks can surface drift early. The rest of this post walks through exactly how that works and what it produces.
Swagger was created as a way to document REST APIs using structured JSON. It defined a vocabulary: here are my endpoints, here are the parameters each accepts, here is what I return if successful, here is what I return if something goes wrong.
A minimal OpenAPI document specifies, for each endpoint: the URL path and HTTP method, the parameters it accepts (type, location, required/optional), the schema of a successful response, and the possible error responses with their codes.
An OpenAPI document is more than documentation — it's a structured definition file (JSON or YAML) that fully describes a REST API's interface. It acts as a contract between API producers and consumers, and because it's machine-readable, the right tooling can parse it, reason over it, and generate real artifacts from it. This distinction matters for everything that follows.
In this post, we show you how to use Kiro, an agentic development system, to automatically generate a complete, runnable Node.js test suite directly from a Swagger API specification -including a mock server, configuration toggles, and HTML test reporting.
If you have worked with OpenAPI specs before, you have probably come across OpenAPI Generator or Swagger Codegen. For context, OpenAPI Generator was forked from Swagger Codegen in 2018 due to governance differences — they share similar goals but are maintained separately with different release cadences and feature sets. Both are open-source tools that take a spec file and generate client libraries, server stubs, or SDK code in your language of choice. They are great for reducing HTTP boilerplate, but they are not designed to verify API behavior. If you try to use them for test generation, you will typically get method stubs with minimal assertions, limited mocking, and little schema validation — though the exact output depends on the language, template, and configuration used. The tests may compile and run, but they often do not provide meaningful coverage of edge cases, error handling, or schema contracts.
This matters more than it sounds. A test with no assertions still passes in CI and counts toward coverage — but it is not actually checking status codes, response shapes, or error cases. You can end up with green builds and high coverage numbers while certain bugs, such as a 400 being returned as a 500, slip through unnoticed.
Kiro approaches the problem differently. Rather than templating from a spec, it reasons over it — resolving enum values into realistic payloads, generating assertions tied to actual schema contracts, and producing a mock server that reflects the spec's defined behavior. The output is not scaffolding to be filled in later; it is executable tests with meaningful coverage.
Capability | OpenAPI Generator | Kiro |
|---|---|---|
Generates executable tests with assertions | ◐ Limited, template-dependent | ✓ Yes |
Builds matching mock server | ✗ No | ✓ Yes |
Infers realistic payloads from schemas | ◐ Partial | ✓ With enum resolution |
Adapts to team coding standards | ◐ Custom templates | ✓ Via steering files |
Regenerates on spec drift in CI | ✗ Manual | ✓ Headless mode |
Understands natural-language intent | ✗ No | ✓ Yes |
Capability comparison: template-based generators vs. Kiro's agent-driven approach.
With a template-based approach, certain classes of issues can go undetected — for example, a 400 error being returned as a 500, or an auth endpoint accepting malformed tokens — particularly when the generated tests make no actual calls to the endpoint and perform no response validation. These tools are primarily designed for code generation, not behavioral verification. Kiro, by contrast, generates tests that exercise each endpoint and verify that the response matches what the spec defines — providing a more reliable signal of actual API conformance.
Our solution takes a sample PetStore Swagger/OpenAPI specification URL as input and uses Kiro to generate a fully functional test project. The generated project includes the following components:
Test client using axios — HTTP tests covering every endpoint defined in the Swagger spec, including GET, POST, PUT, and DELETE operations with appropriate request payloads and response assertions.
Mock Express server — A local server that simulates the API, returning realistic responses for each endpoint so tests can run without network access or dependency on a live service.
Configuration toggle — A simple switch to run the same test suite against the mock server (for local development) or the real API (for integration testing).
HTML test report — A styled, shareable report showing pass/fail status and error details for each test case, suitable for CI/CD pipelines or pull request reviews.
Zero external test frameworks — Tests run on vanilla Node.js with a lightweight custom runner, eliminating framework version conflicts and reducing setup friction.
To follow along with this walkthrough, you need the following:
Node.js
A Swagger/OpenAPI specification URL (we use the Petstore API as our example)
Let’s now generate a complete test suite from the Petstore Swagger specification. Instead of embedding all test generation rules into the prompt, we use a Kiro steering file. Steering files live in “.kiro/steering/” and provide persistent instructions that Kiro follows across all prompts in the workspace. This means you define your test generation standards once and every prompt benefits from them. For this blog we used this sample steering file. Customize it as per your team’s need and standards.
A sample prompt is shown for Kiro’s vibe mode.
Generate a Node.js test suite from https://petstore.swagger.io/index.html using axios, Express for mocking, and no external test frameworks
Kiro reads the Swagger specification, parses every endpoint, and generates the full project.
Kiro produces a project with a structure similar to the following:
config.js — Contains the configuration toggle. Set
useMockServer: trueto run tests against the local Express mock server, oruseMockServer: falseto target the live Petstore API.mock-server/server.js — An Express application with route handlers for every Petstore endpoint. Each handler returns realistic response data matching the schemas defined in the Swagger spec.
test/ — Individual test files organized by API resource (pet, store, user). Each file contains tests for every operation on that resource, with assertions on response status codes and payload structure.
test-runner.js — A lightweight vanilla Node.js test runner that discovers and runs all test files, tracks pass/fail counts and captures error details.
Kiro doesn’t just generate generic test stubs. It reads the Swagger specification and the steering file instructions to:
Identify every endpoint and HTTP method — For the Petstore API, this includes operations like POST /pet, GET /pet/{petId}, PUT /pet, DELETE /pet/{petId}, GET /store/inventory, POST /user/createWithList, and more.
Infer request payloads from schema definitions — For POST and PUT operations, Kiro constructs valid request bodies based on the model definitions in the spec (for example, a Pet object with id, name, category, photoUrls, tags, and status fields).
Generate assertions based on expected response codes — Each test asserts the correct HTTP status code (
200,201,404,405) as defined in the spec’s response definitions.Create corresponding mock server routes — Every endpoint in the spec gets a matching Express route handler that returns data consistent with the defined response schema.
To run the test suite against the local mock server, in the chat interface provide the prompt
“Run the tests with the mock server”.
You will see similar results to what's included below.
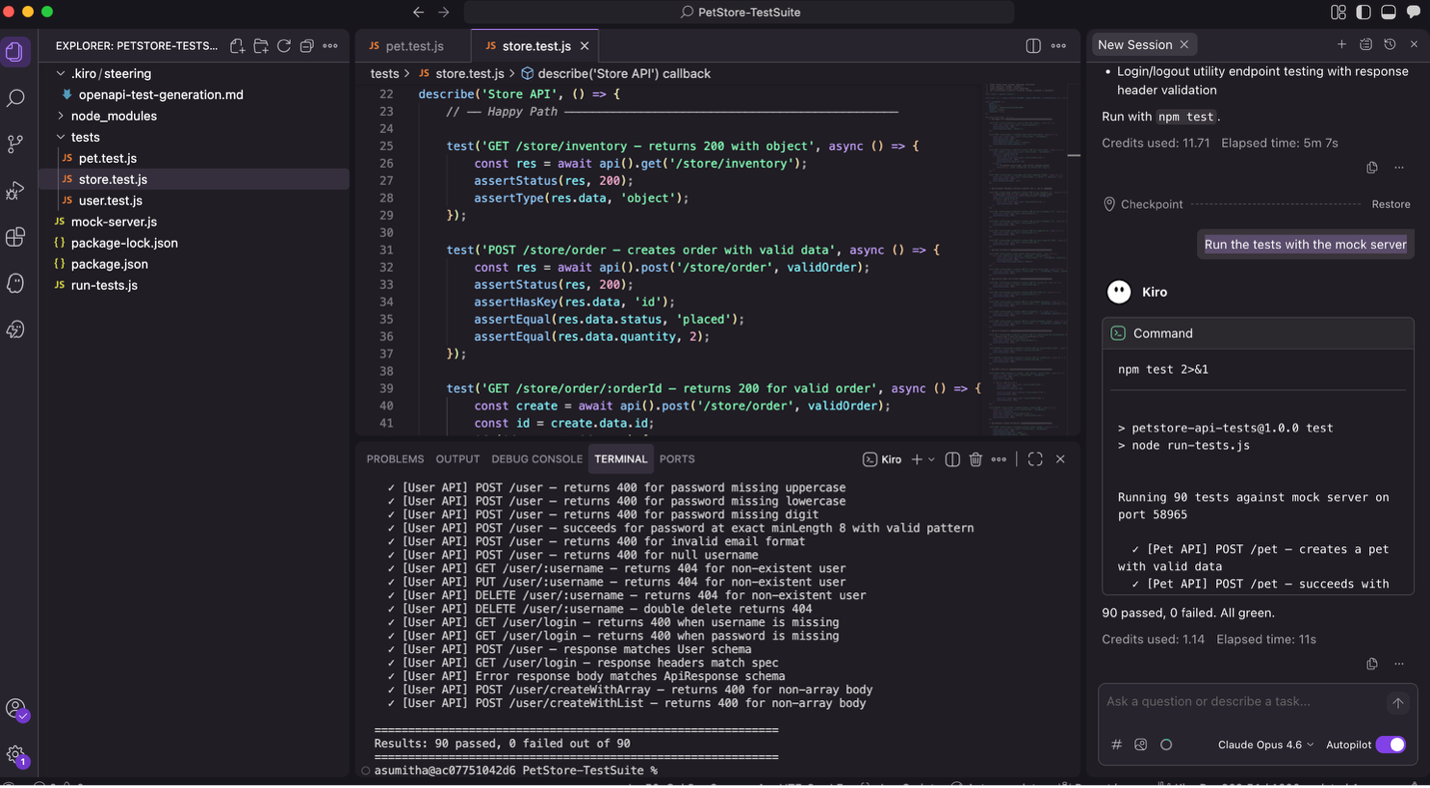
The test runner starts the mock Express server, runs all test cases, and generates the report. Open the generated test-report.md in your browser to view the results.
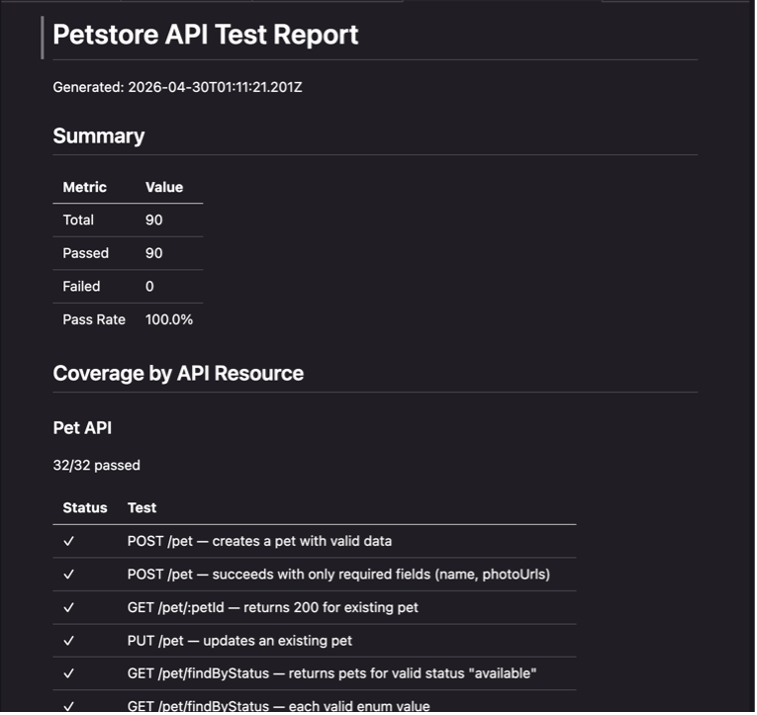
The generated test suite contains test cases covering every endpoint defined in the Petstore Swagger spec. These are integration tests, not unit tests. Each test makes a real HTTP request via axios to a running Express server, exercising the full stack: TCP transport, middleware parsing, route matching, handler logic, state mutation, and JSON serialization. Nothing inside the server is stubbed or mocked at the function level. Several tests even chain multiple requests together — for example, the DELETE tests first POST a resource, then DELETE it, then GET to confirm the 404 — verifying that side effects persist correctly across the request lifecycle. This multi-request, black-box approach is the defining characteristic of integration testing.
On the quality side, the suite has clear strengths. It systematically covers both happy paths and error paths for each endpoint, asserting against the specific HTTP status codes documented in the OpenAPI spec (200, 400, 404, 405). The use of an ephemeral port and in-memory seed data makes the suite fully self-contained and deterministic — no network dependencies, no port collisions, reproducible on any machine. Destructive operations are verified with follow-up reads rather than trusting the response code alone.
In short, this is a practical contract-level integration suite well-suited for fast CI feedback on API shape and error handling. To reach production-grade confidence, it would benefit from per-test state isolation, full JSON schema validation, authentication coverage, and periodic runs against the real service.
One of the more compelling tests Kiro generated goes beyond simply calling an endpoint and checking a status code. It validates an entire resource lifecycle in a single test case:
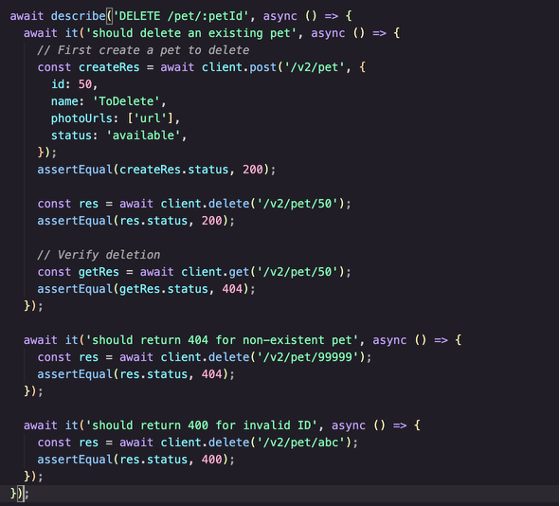
What makes this test interesting is that it doesn't trust the DELETE response alone. Many naive test suites would stop at asserting the 200 status code — "the server said it worked, so it worked." But that proves nothing about whether the state actually changed. A buggy server could return 200 and silently fail to remove the record.
Instead, Kiro generated a three-phase test:
Arrange — POST a new pet with a known ID, confirming it was created successfully.
Act — DELETE that pet and assert the server acknowledges the operation.
Verify — GET the same ID and assert the server now returns
404.
This pattern, sometimes called "round-trip verification", is what separates a meaningful integration test from a superficial one. It proves the API's state machine actually transitions: a resource that exists can be destroyed, and once destroyed, it's genuinely gone. If any layer in the stack (routing, handler logic, data store) silently swallows the deletion, the GET assertion catches it.
It's also a good example of test self-sufficiency. The test creates its own fixture rather than depending on seed data that might have been mutated by an earlier test. This makes the test's pass/fail result independent of execution order, which is a small but important quality signal in a suite without per-test state resets.
To validate whether the generated tests hold up beyond the mock, developers can point the suite at the real Petstore server by setting a single environment variable:
PETSTORE_URL=https://petstore.swagger.io npm test
or prompt kiro with “Run the tests with the real server”. This runs the exact same tests — no code changes required — but now against a live, shared backend instead of the local Express mock.
When failures appear, they typically fall into a few recognizable categories:
The real API is more permissive than the spec. The Swagger definition may document
405for invalid input, but the live server silently accepts it and returns200. The mock was stricter than reality.Error code semantics differ. The mock might return
400for a non-numeric ID while the real server returns404. Both are defensible — they just represent different interpretations of the same spec.Response shapes don't match expectations. A field the test expects as a string comes back as a JSON object, or a nested property is absent entirely.
Shared state assumptions break. Tests that depend on seeded data (like pre-loaded users or pets) fail because the live server doesn't carry those fixtures.
When this happens, the recommendation is not to blindly "fix" the failures. Instead, treat each one as a triage question: is the mock wrong, the test wrong, or the documentation wrong? From there:
If the real server is more lenient, decide whether your mock should relax to match, or whether the test should be tagged as mock-only.
If error codes differ, align on a single source of truth, typically the live server's actual behavior, and update both the mock and the test expectations.
If shared state is the issue, make tests self-sufficient: create their own fixtures before asserting, and don't rely on data that only exists locally.
The point isn't a green pass rate in both modes from day one. It's that running against both targets surfaces where your assumptions diverge from reality — and gives you a structured path to close those gaps.
The Petstore API is a public sandbox that doesn't enforce authentication. Real-world internal APIs almost always do. Here's how to adapt this approach for authenticated endpoints.
First, extend the test configuration to support auth settings. Rather than hardcoding credentials, define them externally so the same suite works across environments:
Then build a shared client factory that attaches the right credentials based on the configured auth type:
Now every test file uses the shared client, and credentials stay out of the code:
With this in place, you can also add dedicated tests that verify auth enforcement itself — that requests without credentials are rejected, that expired tokens return 401, and that insufficient scopes return 403. These are the tests the Petstore sandbox can't exercise, but they're often the most critical for internal services.
Generating a test suite once is useful. Keeping it in sync as the API evolves is where the real value lies. Kiro CLI's headless mode lets you run Kiro programmatically in CI/CD pipelines — no browser, no interactive terminal. You set an API key as an environment variable, pass a prompt, and Kiro executes it end to end.
In this post, we showed you how to use Kiro to generate a complete Node.js API test suite from a Swagger specification in seconds. The generated project includes an HTTP test client, a mock Express server, a configuration toggle for switching between mock and live APIs, and a test report — all without external test framework dependencies.
This approach eliminates the manual effort of translating API specifications into test code and provides a systematic, repeatable way to achieve comprehensive API test coverage. You can apply this same pattern to any API that has a Swagger or OpenAPI specification.
To get started with Kiro, visit kiro.dev.